Reward learning typically relies on a single feedback type or combines multiple feedback types using manually weighted loss terms. Currently, it remains unclear how to jointly learn reward functions from heterogeneous feedback types — such as demonstrations, comparisons, ratings, and stops — that provide qualitatively different signals.
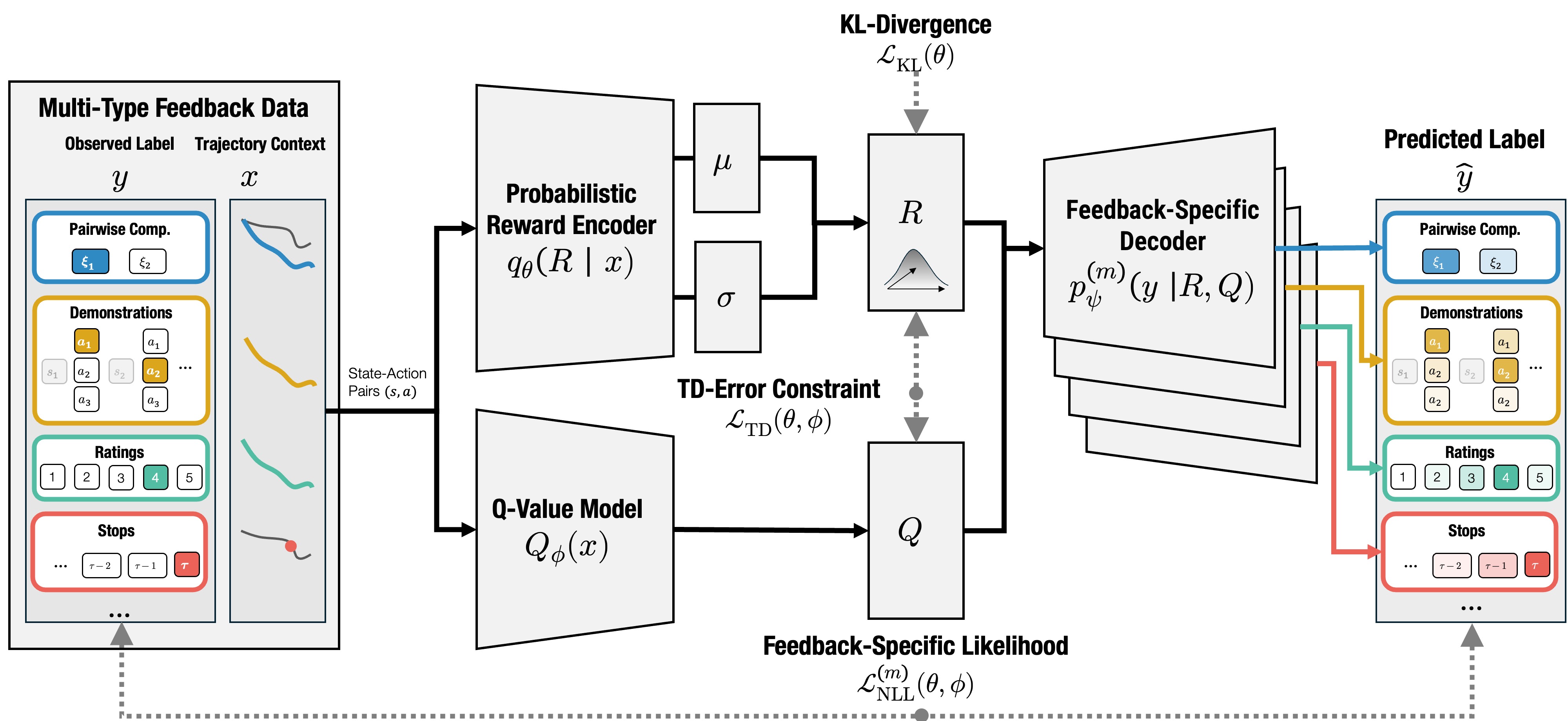
We address this challenge by formulating reward learning from multiple feedback types as Bayesian inference over a shared latent reward function, where each feedback type contributes information through an explicit likelihood. We introduce a scalable amortized variational inference approach that learns a shared reward encoder and feedback-specific likelihood decoders, trained by optimizing a single evidence lower bound.
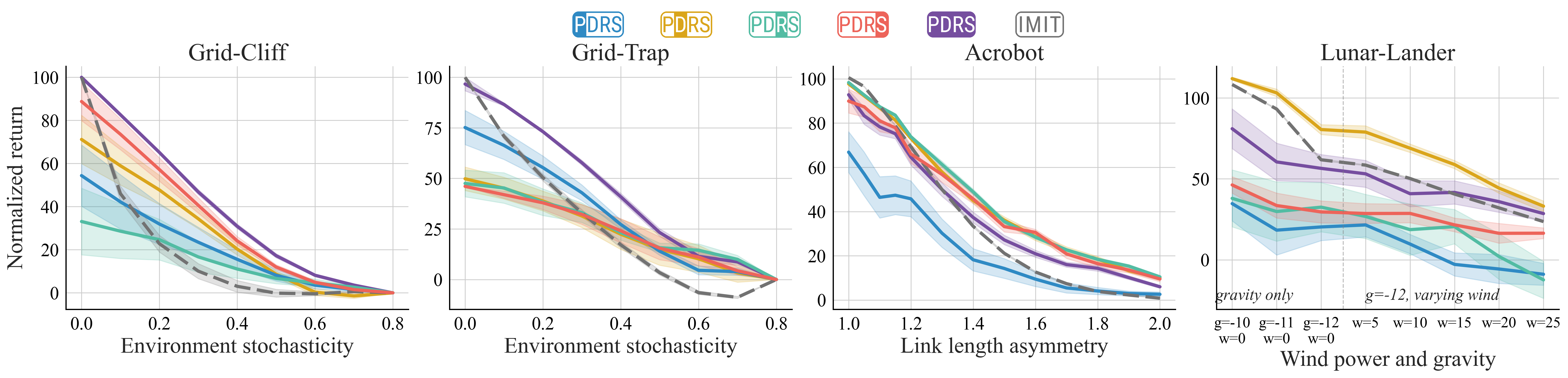
Our approach avoids reducing feedback to a common intermediate representation and eliminates the need for manual loss balancing. Across discrete and continuous-control benchmarks, we show that jointly inferred reward posteriors outperform single-type baselines, exploit complementary information across feedback types, and yield policies that are more robust to environment perturbations.
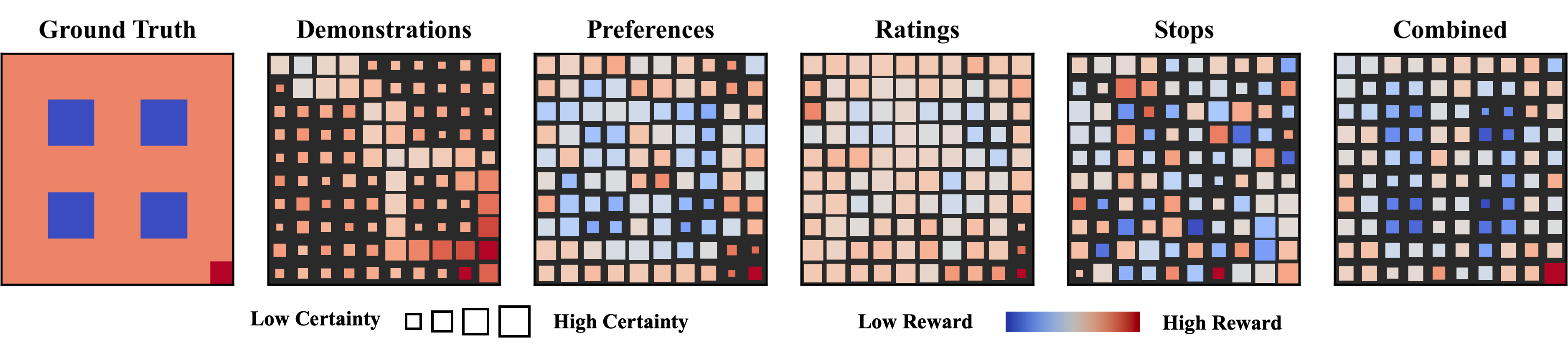
 yield low-uncertainty estimates along expert trajectories but leave large regions underdetermined.
Preferences
yield low-uncertainty estimates along expert trajectories but leave large regions underdetermined.
Preferences  provide broader coverage but can over-reward frequently visited states.
Ratings
provide broader coverage but can over-reward frequently visited states.
Ratings  reliably identify goals but offer limited landscape information.
Stops
reliably identify goals but offer limited landscape information.
Stops  strongly constrain unsafe regions while providing little guidance on desirable behavior.
strongly constrain unsafe regions while providing little guidance on desirable behavior.